import tensorflow as tf
# 데이터에 랜덤한 값을 하나 넣고, 이름을 'weight', 'bias'로 붙여준 Variable을 생성한다.
W = tf.Variable(tf.random_normal([1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
# 들어올 데이터의 타입은 float32, shape은 아직 정해지지 않은 placeholder를 생성한다.
X = tf.placeholder(tf.float32, shape=[None])
Y = tf.placeholder(tf.float32, shape=[None])텐서플로우는 '텐서(Tensor)'를 이용해서 그래프를 구성하고, 그래프에 데이터를 넣어 '흐름(Flow)'을 만드는 컨셉을 가지고 있다. 여기서 텐서는 텐서플로우의 기본 단위가 되는 어떤 구조체(배열)쯤으로 생각하면 좋을 것 같다. 위 코드를 이해하려면, 텐서의 자료형과 속성에 대해 알아야한다. W, b는 학습시킬 변수 두개를, X, Y는 학습에 사용하는 데이터를 넣을 placeholder 두개를 생성했다.
자료형
- constant : 상수를 의미하는 텐서
- Variable : 학습 과정이 진행되면 Tensorflow가 값을 수정하며, 찾고자하는 값으로 나아가게 되는 학습변수이다.
- placeholder : 자료형 constant는 상수로 값을 수정할 수 없지만, placeholder는 나중에 값을 설정할 수 있다.
속성
- Rank : 차원을 의미한다.
(Rank=0인경우 스칼라(값), Rank=1인경우 벡터(1차원배열), Rank=2인경우 행렬(2차원배열)이 된다) - Shape : 정해진 Rank에 어떠한 구조의 데이터가 들어가는지를 나타내는 값이다.
(Shape는 Rank만큼 원소의 개수를 갖게된다. 예를 들어, Rank=2 -> Shape=(3, 5) : 3X5의 행렬) - dtype : 텐서가 가질 데이터 값이 어떤 타입을 갖는지를 의미한다. 주로 float32, int32를 이용하게 된다.
- name : 텐서에 이름을 붙여줄 수 있고 필수는 아니다.
# 가정을 정의한다.
hypothesis = W * X + b
# 비용을 정의한다.
cost = tf.reduce_mean(tf.square(hypothesis - Y))현재 우리가 볼 예제는 인공지능 > 머신러닝 > 지도학습(Supervised Learning)에 해당한다. 복습하자면, 지도학습은 입력에 대한 결과값을 같이 주고 학습시켜, 나중에는 입력값만 받아도 결과를 추론해낼 수 있게 하는 것이다. 위에서 생성한 placeholder X, Y에는 후에 입력값, 입력에 대한 출력값이 각각 들어갈 것이다.
가정
가정은 '입력과 출력사이에 이런 관계가 있을 것이다' 하고 함수식을 세워보는 것이다. 만약 데이터가 선형의 관계를 갖는다고 하면 가정을 H(X) = W*X + b 라고 세울 수 있다. 아까 정의한 W와 b에 초기값은 랜덤으로 들어갔다. 앞으로 학습을 반복하며 W, b는 'X, Y 사이의 관계에 해당하는 값'으로 점점 가까워질 것이다.
( X=[1, 2, 3], Y=[3, 5, 7] 이 학습데이터로 주어졌다면 W=2, b=1에 점점 가까워진다)
비용함수
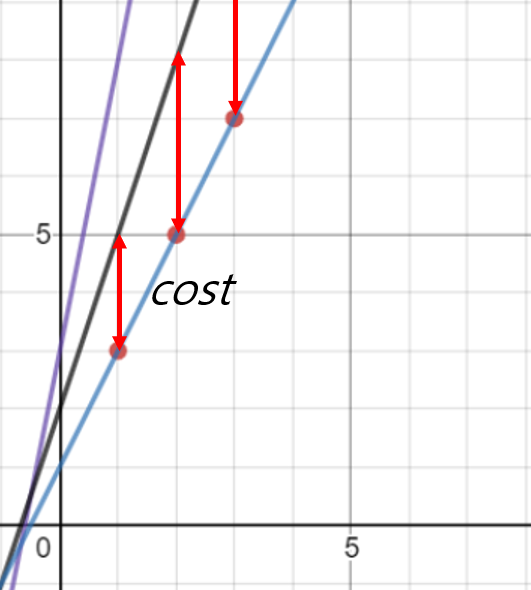
그렇다면 어떻게 W, b를 파란색 정답직선에 근사시킬 수 있을까? 세운 가정에서의 H(X)값과 실제 학습데이터 Y값의 차이를 최소화하는 것이다. 이 때, 부호와 관계없이 차이를 보고싶은 것이므로 square() 을 이용해 값을 제곱해준다. reduce_mean() 으로 값을 모두 더한 뒤 데이터의 갯수만큼 나눠주면 비용(cost)가 정의 된다.
그렇다면 앞으로 이 코드의 목적은 비용을 최소로 줄이는 것이 된다. 비용이 최소가 된다는 것은 가정한 직선과 실제 데이터 값 간의 차이가 최소화 된다는 말이 되기 때문이다.
# 원래는 다음과 같은 과정을 거쳐 cost의 최솟값을 찾아가야 한다.
# 설명을 위해 간단한 예 H(X) = W * X로 가정했다.
'''
learning_rate = 0.1
gradient = tf.reduce_mean((W * X - Y) * X)
descent = W - learning_rate * gradient
update = W.assign(descent)
'''
# 하지만 텐서플로우는 이 과정이 친절하게 구현되어 있다.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train = optimizer.minimize(cost)먼저 위 코드에서 밑에서 두번째 줄을 보자.
GradientDescentOptimizer 는 경사(Gradient)를 하강(Descent)하며 최적의 값, 즉 여기서는 최솟값을 찾아주는(Optimizer) 함수라는 의미를 갖고 있다. 무슨 경사를 왜 하강한다는 말일까, 또 매개변수로 주어진 learning_rate 는 무슨 말일까?
경사하강 알고리즘
먼저 무슨 경사를 어떻게 하강하는지 알아야한다. 예를 들어, H(X) = W*X 라고 가정하자. 비용(cost)을 계산할 때, X와 Y는 어차피 주어져있는 데이터이므로, 가정(hypothesis)에 따라 값이 좌우 된다. 또 가정은 결국 기울기인 W에 의해 직선의 모양이 바뀌게 된다. 따라서 cost는 W에 관한 함수 cost(W)라고 말할 수 있다.

만약 가로축을 W로, 세로축을 cost라고 한다면 그래프는 다음과 같이 그려진다. 우리는 처음 W를 random_normal([1])로 초기화했었다. 이때 3이 초기화됐다면, (3, cost(3)) 부터 시작해서 접선의 기울기(경사)를 타고 내려가며(하강) 비용의 최솟값을 찾을 것이다.
- W = W - learning_rate * gradient
learning_rate는 하강간격을 조정하기 위한 양수인 상수이다. gradient는 접선의 기울기를 의미한다. 양수의 곱이므로, W는 원래의 값보다 줄어든 값으로 업데이트 될 것이다. - 이를 계속 반복하면 꼭짓점을 향해 하강하게 된다.
- 꼭짓점에 가까워질수록 접선의 기울기가 감소해 변화량이 작아진다.

하지만, 잠깐 새로운 그래프를 보자. 만약 빨간 점부터 하강을 시작한다면, 위의 알고리즘으로 생각해 봤을 때, 비용의 최솟값이 아님에도 불구하고 노란 부분에 근사할 것이다.
따라서 경사하강법은 convex function이라는 특정 조건을 만족시킬때만 사용이 가능하다. 볼록함수(convex function)에 대한 설명이 잘 나와있는 동영상이다(링크)
위의 코드에서 주석처리 되어있는 부분은 경사하강법을 이용해서 cost의 최솟값을 구하는 그래프를 직접 만든 것이다. 하지만 tensorflow에서 제공하는 GradientDescentOptimizer()함수를 사용하면 학습율과, 최소화할 대상을 지정하는 것 만으로 쉽게 사용할 수 있다. 알아서 경사를 계산하고, 하강을 하며, 그 값을 W에 업데이트한다.
# 그래프를 실행할 세션을 만들어준다.
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 학습은 2000번 진행한다.
for step in range(2001):
cost_val, W_val, b_val, _ = sess.run([cost, W, b, train],
feed_dict={X: [1, 2, 3, 4, 5],
Y: [2.1, 3.1, 4.1, 5.1, 6.1]})
# 20번에 한 번씩 학습결과를 출력해준다.
if step % 20 == 0:
print(step, cost_val, W_val, b_val)텐서플로우는 텐서(Tensor)로된 그래프를 만들고 데이터를 넣어 흐름(Flow)을 만드는 언어이다.
세션을 만들고 실행하기 전에, 현재 구성되어 있는 그래프를 그려보면 이러하다.

텐서보드를 이용해 출력한 그래프이다. 연산노드들을 거쳐 데이터가 흐르게 되고, GradientDescentOptimizer가 W, b에 붙어 학습한 정보를 바탕으로 수정할 것임을 확인할 수 있다. 위 코드에서는 sess.run( [ ..., train, ... ])을 실행하면 train = optimizer.minimize(cost)부터 시작하여 그래프에 흐름이 생길 것이다. 출력된 결과는 다음과 같다.

X ←[1, 2, 3, 4, 5 ]
Y ←[2.1, 3.1, 4.1, 5.1, 6.1] 가 입력되었으므로,
어림잡아 보았을 때, y = x + 1.1 의 직선, 즉 W = 1, b = 1.1이면 훌륭하게 학습을 했다고 할 수 있을 것이다. 2000번의 학습결과 꽤나 훌륭하게 학습이 되었다.
앞선 게시물에 링크했던 '모두를 위한 딥러닝' 강의를 듣고 필기한 노트에
추가적으로 공부한 것을 더해 작성한 게시글입니다.
'💻 > ML' 카테고리의 다른 글
| [모두를 위한 딥러닝] 다중 분류, 소프트맥스 회귀 (0) | 2020.08.03 |
|---|---|
| [모두를 위한 딥러닝] 로지스틱 회귀 (0) | 2020.07.27 |
| [모두를 위한 딥러닝] 작업환경 설정(파이썬, 텐서플로우) (0) | 2020.07.26 |
| [모두를 위한 딥러닝] 인공지능, 머신러닝 (0) | 2020.07.26 |
| [머신러닝] 공부 시 참고 링크 (0) | 2020.07.25 |