공부시간(X)을 늘리면 더 좋은 성적(Y)을 받는 것은 통계적으로 합당할 것이다. 1시간 공부한 사람은 20점, 3시간 공부한 사람은 60점, 4시간 공부한 사람은 80점을 받고, 이는 선형적인 관계에 있다고 할 수 있다. 하지만 모든 데이터가 항상 이런 선형적인 관계에 있는 것은 아니다.
로지스틱 회귀
합격과 불합격으로만 결과가 나오는 P/F 상황을 가정해보자.
1시간 ~ 3시간 공부한 사람은 불합격을 받고, 4~6시간 공부한 사람은 합격을 받았다. 합격=1, 불합격=0 으로 봤을 때 다음 상황을 X=[1, 2, 3, 4, 5, 6], Y=[0, 0, 0, 1, 1, 1] 로 말할 수 있고, 이 데이터를 학습에 이용할 수 있을 것이다.

평소처럼 우리가 H(X) = X*W + b로 가정을 한다면 다음과 같이 결과를 얻은 뒤, y좌표가 0.5가 넘어가면 1(합격), 그렇지 않다면 0(불합격)으로 판단할 수 있다. 이 판단이 합리적으로 보일 수 있지만 사실은 몇가지 불편한 점이 있다.
- 위 직선에서 100시간 공부한 사람이 합격한 경우((100, 1))이 학습데이터로 주어진다면, 비용을 줄이기 위해 직선의 기울기는 더 줄어들 것이고 이는 4시간 공부한 사람이 불합격 할 것이라고 잘못된 예측을 할 수도 있다.
- 애초에 값이 0과 1이면 되는데, 위 직선에서 500시간을 공부했다면 Y는 약 100의 값을 갖게 될 것이고, 이를 다시 1로 고쳐줘야 한다. 모양이 좋지 않다.
X = tf.placeholder(tf.float32, shape=[None, 2])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([2, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# W와 X의 곱은 shape이 클 경우 행렬의 곱으로 정의하는 것이 좋다.
# 만든 가정을 sigmoid함수에 넣어준다.
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
가정
따라서 우리는 새로운 가정을 만들어줄 필요가 있다. 먼저 기존에 사용하던 가정 H(x) = Wx + b 를 0과 1사이의 값으로 적절히 변환해주는 필터에 넣어줄 것이다.

이 함수는 Sigmoid 라고 하며, 입력값이 커지면 1에 가까워지고, 입력값이 작아지면 0에 가까워지게 된다. 우리는 학습에 과정을 하나 추가하여, H(x) = Wx + b 가정을 생성하고 y = Sigmoid(x) 함수에 H(x)를 입력값으로서 넣어 새로운 가정 H'(x) = Sigmoid(H(x)) 만들 것이다. 이 새로운 가정 H'(x)는 H(x)의 값이 커질 수록 1에 가까워지고, 작아질 수록 0에 가까워진다.
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) *
tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)비용함수
다음 스텝은 새로운 가정에 대하여 새로운 비용을 정의하는 것이다. 기존의 방식대로 비용을 구한다면, y = cost(W)의 그래프는 볼록함수가 아닌 정체모를 함수가 나올 것이다. 그럼 경사하강법을 적용해 최저비용점을 찾는데 문제가 생기기 때문에 새로운 방법을 찾아야 한다. 방법을 찾기 위해서 먼저 가정과 데이터 사이의 오차를 계산하던 기존의 방법을 바꾼다.
$$(H(x) - Y)^{2}\to{ c\ (H(x), y) }\\\\{ c\ (H(x), y) } \cases{ -log(H(x))\ \ \ \ \ \ \ \ \ \ :y=1 \\ -log(1-H(x))\ \ \ :y=0 }$$
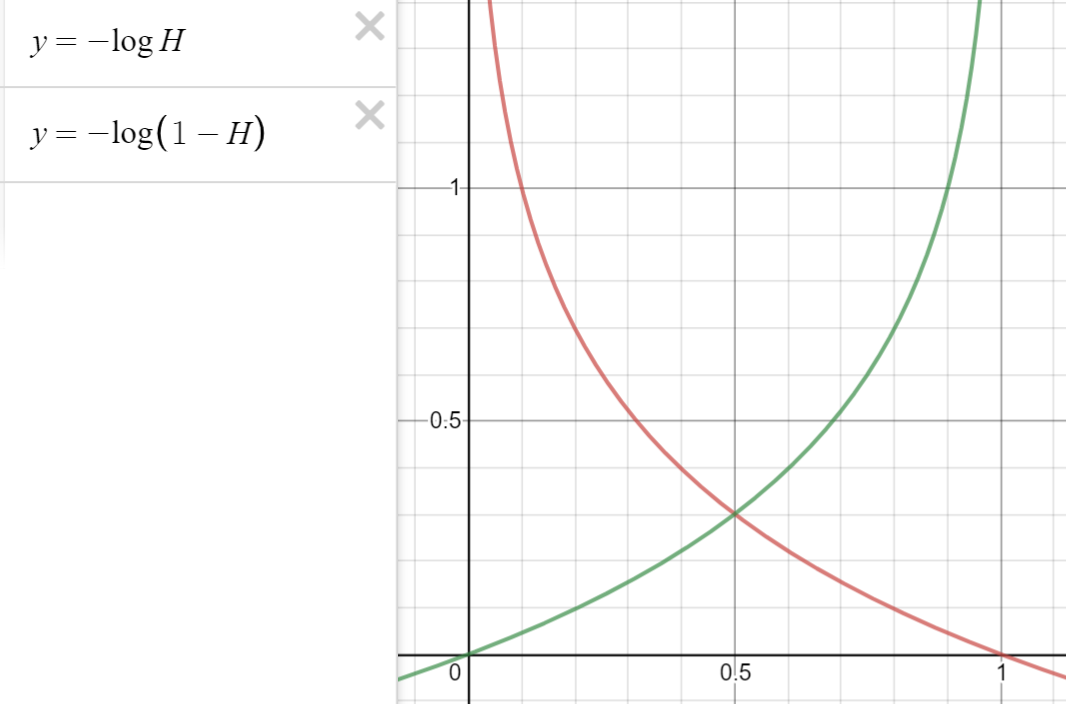
- y=1인 경우, signoid 필터를 거친 H(x)는 0부터 1사이의 값을 갖는다. H(x)가 0에 가까워질 수록 비용은 점점 커질 것이고, H(x)가 1에 가까워수록 비용은 작아질 것이다.
- y=0인 경우, H(x)가 0에 가까워질 수록 비용은 점점 작아질 것이고, H(x)가 1에 가까워수록 비용은 작아질 것이다.
$${ c\ (H(x), y) } = -y \times log(H(x)) -(1-y)\times log(1-H(x))$$
이 비용함수는 실제 데이터 y에 가정이 가까워질수록 비용이 점점 작아지는 것을 보니, 제대로 설계되었다고 할 수있다.비용함수가 정의되었으니 나머지 과정은 tensorflow가 알아서 착착착 해줄것이다.
# Accuracy computation
# True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
# Launch graph
with tf.Session() as sess:
# Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
cost_val, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, cost_val)
# Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy],
feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a)
결과적으로 코드의 흐름을 정리해보면 이렇다.
- 가정(초록 그래프)을 sigmoid 함수에 필터시켜 0~1 범위로(보라 그래프) 만들어 준다.
- 가정과 Y의 오차, 즉 비용을 계산할 때에는, Y값에 따라 함수(- log(X) / - log(1-X) )를 선택해 가정을 대입해준다.
- 결과를 모두 더해 데이터셋의 개수로 나눠 최종적으로 비용을 구한다.
- 경사하강법을 사용해 비용의 최저점을 찾아가며 W, b를 학습한다.
앞선 게시물에 링크했던 '모두를 위한 딥러닝' 강의를 듣고 필기한 노트에
추가적으로 공부한 것을 더해 작성한 게시글입니다.
'💻 > ML' 카테고리의 다른 글
| [모두를 위한 딥러닝] 학습계수, 데이터 표준화, 과적합 (0) | 2020.08.04 |
|---|---|
| [모두를 위한 딥러닝] 다중 분류, 소프트맥스 회귀 (0) | 2020.08.03 |
| [모두를 위한 딥러닝] 텐서플로우 기초, 선형회귀 (0) | 2020.07.26 |
| [모두를 위한 딥러닝] 작업환경 설정(파이썬, 텐서플로우) (0) | 2020.07.26 |
| [모두를 위한 딥러닝] 인공지능, 머신러닝 (0) | 2020.07.26 |